This article serves as a basement for my future posts. Here I explain how I manage data flow in a functional application.
I’m a big fan of functional programming. I find it more readable, safer, easier to refactor. I often think of what can I bring into my application to make it more functional. Let me show how I organize a program by looking at a very simple yet real code. It’s a very small simplified fraction of Vulkan initialization (details are missed for brevity). To create a VkShaderModule a VkDevice object is needed. The VkDevice requires VkInstance. The code should flow sequentially - one operation should not start until the previous is finished. On paper it looks like this:

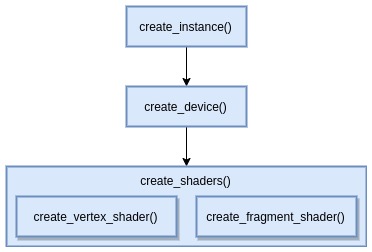
Base requirements for the program are:
create_device()never starts before or at the same time withcreate_instance().create_shaders()should wait untilcreate_device()is complete - same as before.- the code inside
create_shaders()can run concurently, i.e. vertex and fragment shader creation can run in parallel.
Here my thoughts about program organization:
- each function lives in its file. This of course not mandatory but I prefer to keep unrelated things separate. And yes - there’s a huge amount of files even for a decent application. But they are quite small and easy to read/navigate.
- it would be good to have some guarantees that functions that share a data don’t run in parallel. Or maybe the other way around - the data sharing should be limited.
- I prefer to keep the code flow as much linear as possible. Instead of jumps or callbacks, I prefer to accumulate state changes and resolve them on the next step (I will not touch this in the article).
To make data easy to work with I keep it in a single struct and pass that struct back and forth filling it with objects.
struct AppData
{
VkInstance instance{VK_NULL_HANDLE};
VkDevice device{VK_NULL_HANDLE};
VkShaderModule vertexShader{VK_NULL_HANDLE};
VkShaderModule fragmentShader{VK_NULL_HANDLE};
};The question is how to safely pass the data to and out of functions? Let’s explore the available options and start with an agreement to pass every parameter by value.
Pass by value
This is the simplest and safest way to pass the data around. I have a guarantee that the application is thread-safe since each thread operates on its copy of data. And when I update the data I return a copy of it:
AppData create_instance(AppData data)
{
data.instance = ...;
return data;
}
AppData data{};
data = create_instance(data);
data = create_device(data);
data = create_shaders(data);I see a problem here with too much copying. The data can be big and making a copy will destroy the performance. Another issue (not the case in my example) is that if the struct misses a copy constructor the code will not compile. Next, let’s pass by reference.
Pass by reference
Since I want to stay in a functional paradigm I’d like to avoid non-constant references as they break some functional programming rules. So the obvious solution is a reference to const. Now passing doesn’t make a full copy but I still need to do it in the function’s body to return the modified data.
AppData create_instance(AppData const & data)
{
AppData dataCopy{data};
dataCopy.instance = ...;
return dataCopy;
}
AppData data{};
data = create_instance(data);
data = create_device(data);
data = create_shaders(data);Still the same issue with lots of copies. But what if I guarantee that each function is a unique owner of the data? That means that the data race is impossible since the data exists in a single instance. I can do it by moving the data to and out of a function.
Pass by r-value reference
AppData && create_instance(AppData && data)
{
data.instance = ...;
return std::move(data);
}
AppData data{};
data = foo(std::move(data));
data = foo(std::move(data));
data = foo(std::move(data));Though it does the job it looks ugly. Moreover, if the move constructor is not present, the code will not compile. Or if the move assignment operator deleted the code will silently use the copy assignment. Finally, if fields are not movable (like in my case) they will be copied. Fortunately, it’s still possible to improve.
Pass by std::unique_ptr
With it, the code will take its final look.
std::unique_ptr<AppData> create_instance(std::unique_ptr<AppData> data)
{
data->instance = ...;
return data;
}
auto data{std::make_unique<AppData>()};
data = create_instance(std::move(data));
data = create_device(std::move(data));
data = create_shaders(std::move(data));Now it will compile with deleted copy and move constructor, with const field members, etc. It will be fast since only copying that happens is std::unique_ptr copying which is fast. But what I like more is the code brevity - it explicitly tells the reader the intentions - hey, the data is moved so don’t use it until you read it back from the function.
Now you may ask - you talked so much about multithreading but now multithreading is even impossible if you can’t share the data. And yes you’re right - what I did is forced the application to be sequential. Exactly what I needed for the sequential initialization. And now I can sleep safe knowing there are no data races. But if I go inside any function - I can do there whatever I want since I know I’m the only owner of the data. This is how I’d implement create_shaders:
namespace
{
enum class ShaderType
{
fragment,
vertex
};
VkShaderModule create_shader(AppData const & data, ShaderType const shaderType)
{
VkShaderModule shaderModule = ...;
return shaderModule;
}
}
std::unique_ptr<AppData> create_shaders(std::unique_ptr<AppData> data)
{
auto vertexShader = std::async(&create_shader, std::ref(*data), ShaderType::vertex);
auto fragmentShader = std::async(&create_shader, std::ref(*data), ShaderType::fragment);
data->vertexShader = vertexShader.get();
data->fragmentShader = fragmentShader.get();
return data;
}Notice how the create_shader() is hidden from the outside world in the anonymous namespace. Of course, it’s possible to break the code but now I need to try hard and it would be difficult to do so by accident.
Now we know how to pass data safe and fast and how to return it. But what if a function fails? How to tell that to a caller?
Exceptions
In theory, all three functions can fail.
data = create_instance(std::move(data));
data = create_device(std::move(data));
data = create_shaders(std::move(data));Of course, I don’t want to execute create_device() in case create_instance() fails because of dependency between them. Of course, I need to know why the error happened. Also, I’d like to react to the error - at least I need to clean the already created objects.
Let’s explore again different options to handle errors.
Return nullptr
Since I’m using an std::unique_ptr I can encode an error via nullptr value. Here’s how the code would look with it:
data = create_instance(std::move(data));
if(!data)
do something
data = create_device(std::move(data));
if(!data)
do something
data = create_shaders(std::move(data));
if(!data)
do somethingPros:
- very easy to implement.
Cons:
- a lot of spaghetti.
- fail reason is unknown and I need another way to report it. For example, some global variable can be filled with a message - but this is very error-prone, there’s no guarantee the function sets this value.
- no clean way to destroy already created objects since everything we got after a broken call is a
nullptr. Again, I need to store the half-filled data in some global variable and use it on program exit. - no easy way to tell if a function fails or not by just looking at its signature. In other words, the code is not expressive.
Return std::optional
std::optional<std::unique_ptr<AppData>> create_instance(std::unique_ptr<AppData> data)
{
if(something wrong)
return std::nullopt;
return data;
}Very similar to the previous method. The only difference is that the latter is more expressive - it tells us directly that a function can fail and this is easy to see just looking at the function’s signature.
Pros:
- expressivity. Now looking at the function’s signature it’s clear if a function can fail or not.
Cons:
- same as before.
Return some sort of expected
Why some sort? Because it’s not a part of the standard (at the moment of writing) and one has to choose from available implementations or write by him/herself. I’m using tl::expected from TartanLlama a lot (read more about the implementation here). It has the expressivity as std::optional but provides an unexpected value in case of error. So it’s possible to return the half-filled data to clear it. In code it looks like this:
struct AppDataError
{
std::string what{};
std::unique_ptr<AppData> data{};
}
using MaybeData = expected<std::unique_ptr<AppData>, std::unique_ptr<AppDataError>;
MaybeData create_instance(std::unique_ptr<AppData> data)
{
if(something wrong)
return make_unexpected(std::make_unique<AppDataError>("failed to create instance", std::move(data)));
return data;
}
// other functions
auto maybeData{create_instance(std::move(data))};
if(!maybeData)
{
auto error{std::move(maybeData.error())};
std::cout << error.what << std::endl;
clear(std::move(error.data));
return;
}
maybeData = create_device(std::move(*maybeData));
if(!maybeData)
{
auto error{std::move(maybeData.error())};
std::cout << error.what << std::endl;
clear(std::move(error.data));
return;
}
maybeData = create_shaders(std::move(*maybeData));
if(!maybeData)
{
auto error{std::move(maybeData.error())};
std::cout << error.what << std::endl;
clear(std::move(error.data));
return;
}So the error has a message which can indicate the fail reason and the so far filled data which can be cleared. The only annoying thing left is the repetitive condition block after each function call. For this, the tl::expected have a very handy method and_then which can chain multiple function invocations. But if the very first fails, all others will not be executed. With this the code takes its final form:
// as before
auto maybeData{create_instance(std::move(data))
.and_then(create_device)
.and_then(create_shaders)};
if(!maybeData)
{
auto error{std::move(maybeData.error())};
std::cout << error.what << std::endl;
clear(std::move(error.data));
return;
}I find this beautiful. The only thing to take into account is that all the functions should have the same signature to make this chaining work.
Pros:
- fail reason is known and bound to the return type.
- half created objects can be cleared.
- expressivity - it’s possible to tell if a function fails looking at its signature. If expected is returned - it can fail, if an object is returned - it never fails (but still can be chained with
mapfunction).
Cons:
- not a standard (so-so point, but I had to write something).
Throw an exception.
Very very similar to the expected option. There’s no chaining like in the previous case, but with exceptions, the control flow jumps into the catch block, so there’s no need to wrap every function in the try/catch block. Instead of this:
AppDataPtr appData{std::make_unique<AppData>()};
try
{
appData = create_instance(std::move(appData));
}
catch (std::exception const & error)
{
// handle error
}
try
{
appData = create_device(std::move(appData));
}
catch (std::exception const & error)
{
// handle error
}
try
{
appData = create_shaders(std::move(appData));
}
catch (std::exception const & error)
{
// handle error
}We can write this:
AppDataPtr appData{std::make_unique<AppData>()};
try
{
appData = create_instance(std::move(appData));
appData = create_device(std::move(appData));
appData = create_shaders(std::move(appData));
}
catch (std::exception const & error)
{
// handle error
}Another cool thing with exceptions is that we can nest them one into another so it’s possible to follow an exception call stack. std::throw_with_nested have a nice example of how to use it.
There’s no big difference between expected and exception approach - fail reason is known, we can clean after an exception, the expressiveness still in place - if noexcept specifier is used we know for sure a function doesn’t throw. But I’d prefer the exception case` since it’s a standard and doesn’t require to use a third-party library.
With everything applied the pseudo-code architecture finally becomes:
// AppData.hpp
struct AppData
{
VkInstance instance{VK_NULL_HANDLE};
VkDevice device{VK_NULL_HANDLE};
VkShaderModule vertexShader{VK_NULL_HANDLE};
VkShaderModule fragmentShader{VK_NULL_HANDLE};
};
using AppDataPtr = std::unique_ptr<AppData>;
struct AppDataError : public std::exception
{
AppDataError(std::string msg, AppData && ptr) : message{std::move(msg)}, appData{std::move(ptr)}
{}
const char *what() const noexcept override
{
return message.c_str();
}
std::string message{};
AppData appData{};
};// create_instance.cpp
AppDataPtr create_instance(AppDataPtr data)
{
if(something wrong)
throw AppDataError{ERROR_MESSAGE("failed to create instance"), std::move(*appData.release())};
return data;
}// create_device.cpp
AppDataPtr create_device(AppDataPtr data)
{
if(something wrong)
throw AppDataError{ERROR_MESSAGE("failed to create device"), std::move(*appData.release())};
return data;
}// create_shaders.cpp
VkShaderModule create_shader(std::string const &fileName)
{
if(something wrong)
throw std::runtime_error{ERROR_MESSAGE("failed to open shader file " + fileName)};
return shaderModule;
}
AppDataPtr create_shaders(AppDataPtr data)
{
// can run in parallel
// vertex shader
try
{
data->vertexShader = load_shader("VertexShader.spv");
}
catch (std::runtime_error const & /*error*/)
{
std::throw_with_nested(AppDataError{ERROR_MESSAGE("failed to get vertex shader data"), std::move(*appData.release())});
}
// fragment shader
try
{
data->vertexShader = load_shader("FragmentShader.spv");
}
catch (std::runtime_error const & /*error*/)
{
std::throw_with_nested(AppDataError{ERROR_MESSAGE("failed to get fragment shader data"), std::move(*appData.release())});
}
return data;
}// clean.cpp
void clean(AppData && appData) noexcept
{
// doesn't throw
}// main.cpp
void handle_error(std::exception const & error, uint32_t const level = 0)
{
std::cout << std::string(level, ' ') << error.what() << '\n';
try
{
std::rethrow_if_nested(error);
}
catch(std::exception const & nestedError)
{
handle_error(nestedError, level + 1);
}
catch(...)
{
std::cout << "unknown error" << '\n';
}
}
int main()
{
AppDataPtr appData{std::make_unique<AppData>()};
try
{
appData = create_instance(std::move(appData));
appData = create_device(std::move(appData));
appData = create_shaders(std::move(appData));
}
catch (std::exception const & error)
{
handle_error(error);
// clean whatewer we have in appData
clean(std::move(error.appData));
return 1;
}
clean(std::move(*appData.release()));
return 0;
}The code is safe, modular, extendable, easy to read and navigate, fast. Maybe there’s a bit of a typing but I got used to it and that doesn’t annoy me. I’ll use the approach in the upcoming article series.
Update: some time later after I started the article I found that I invented Rust in c++. I’m pretty happy that I’m not only the one in the Universe who thinks similarly. Btw, I’m learning Rust and already fell in love with it. So maybe new posts will be based on Rust as a language?