Today we’ll fight with the final boss and save the princess. We’ll finally see our teapot on the screen.
Let’s remember what we did - we initialized Vulkan, created shaders, created resources and uploaded data on the GPU, created pipelines, swapchain, and framebuffers. In this step, we’ll use all this information and instruct the GPU to execute the shaders. The draw function lives in the draw.rs file in the teapot workspace. And here are the actions we need to take to draw our object:
- We have multiple images in the swapchain. We need to find the index of the next available image in the swapchain - it will be used by some functions.
- We have multiple resources in flight - we need this because we don’t want to wait until the GPU is done with a previous frame, so we prepare another meanwhile. But since the CPU may finish its job faster, we have to wait until the resources are safe to reuse.
- As we already saw, we tell the GPU what to do by recording commands to a command buffer, and later we submit that buffer. We need to get a command buffer and begin the recording.
- Some commands (for example,
cmd_draw_indexed) can be used only inside the render pass scope, so we need to begin a render pass. - When we created pipelines, we specified some states as dynamic (it was the viewport and the scissor states). We must set these states.
- We have a list of buffers, and a descriptor set layout, but until this point, we didn’t tell the GPU which resource to use for what. We only described the types of resources for the pipeline. We need to get a descriptor set and update it with the real objects.
- We decided to update an MVP matrix via a uniform buffer. We need to write the new matrix data that will be used in a shader.
- We decided to update a tesselation level via a push constant.
- We need to bind everything together - the updated descriptor set, the pipeline, the index buffer.
- Draw!
- Every started render pass should be ended.
- Every started command buffer should be ended.
- We must submit the recorded command buffer to the queue.
- Finally, we can present the swapchain image on the screen.
Don’t be afraid of the number of actions. They all are pretty simple, and as usual, we’ll walk through all of them step by step. For simplicity, I have moved all the code related to drawing to a separate module (vulkan_draw in the teapot workspace). Let us open the draw function and go through it line by line.
Getting swapchain image index
We get the index using the vulkan_draw::get_image_index function. Here we call the function ash::extensions::khr::Swapchain::acquire_next_image. As you can see from the abbreviation khr, this function is not part of the core Vulkan and should be enabled with the extension VK_KHR_swapchain that we added in the previous step. Here we provide:
- our swapchain.
u64:: MAXnanoseconds (a special value that means infinite time) we are ready to wait for the available image.- a semaphore.
The last point is something new - we have never seen anything like this before. In Vulkan there are several synchronisation primitives and Semaphore is one of them. The Specification states:
Semaphores can be used to control resource access across multiple queues.
In other words, a semaphore “lives” entirely in the GPU and enables synchronisation between queues.
Even if acquire_next_image returns an index, the image can still be “busy”:
The presentation engine may not have finished reading from the image at the time it is acquired
This sounds strange - why return something that is not yet ready? Rendering into this image is an undefined behaviour. But this is done for performance reasons. The combination of index + semaphore “allows rendering operations to be recorded and submitted before the presentation engine has completed its use of the image”. So we need to provide an unsignalized semaphore to this function and when an image can be used, it will be signalled. Remember this semaphore - it will be used later in the draw function.
Note: it is possible to use a fence instead of a semaphore. A fence can be signaled on the GPU while waiting on the host. So we can pass a fence to the function and wait some time later for the presentation engine to mark the fence as signaled so we can use the image. Of course, this GPU-CPU trip is expensive and should only be used in rare cases, such as when reading a swapchain on the host.
This semaphore is called image_available_semaphore and is stored as part of teapot::VulkanData. We create it using the vulkan_utils::create_semaphore function. We use the default information in the ash::Device::create_semaphore function.
Another interesting thing is that acquire_next_image returns a tuple of an index and a bool if successful. In C, it can return the result VK_SUBOPTIMAL_KHR. The Specification says:
If an image is acquired successfully, vkAcquireNextImageKHR must either return
VK_SUCCESS, orVK_SUBOPTIMAL_KHRif the swapchain no longer matches the surface properties exactly, but can still be used for presentation.
This can happen, for example, if we have resized a window and we have a new size but an old image. In this case, we return from the draw function and on the swapchain is rebuilt in the next frame.
Waiting for resources
Waiting until resources are safe to use is done in the wait_resource_available function. Here we call the function ash::Device::wait_for_fences. We pass in a fence, say we want to wait for all fences passed in (we only have one, so false would be fine too) and the wait time is specified as u64:: MAX nanoseconds.
But what is this fence? Let us take a uniform buffer as an example and see how it behaves across multiple frames:
- Recall that we have 2 uniform buffers - one for each frame in flight. At frame 0, we want to update the first buffer. Since this is the first frame, the resource has not yet been used, so we can safely write to it.
- We do not want to wait until frame 0 is fully processed. Instead, we prepare frame 1. We update a second buffer. Since the resource has not been used yet, we can safely write to it.
- Now interesting - at frame 2, we have no more free buffers. Also, we can not guarantee that the GPU has finished the first frame. Yes, GPU work can be hard, but CPU can be fast enough to complete all tasks. This is where the fences help us. When we submit work at the end of a frame, we can submit a Fence - a synchronisation primitive that is signalled on the GPU but listened to on the CPU. So we need as many fences as there are frames in flight (and as many buffers), and at the end of each frame we submit a fence corresponding to a current resource index. In other words, we have a circular buffer of frames, and in our case with 2 frames in flight, these indexes will be 0-1-0-1-0-1-etc. So at frame 2 ( remember, we start at 0) we wait for the 0th fence. When it is signalled, we can safely update the 0th buffer.
- At frame 3, we wait for the fence that was submitted in frame 1, and so on.
These fences are stored in teapot::VulkanData and are created in the function teapot::create_fences function. Here we call the function ash::Device::create_fence asking to create fences in the state ash::vk::FenceCreateFlags::SIGNALED so that the first call to wait_for_fences is not blocked but returned immediately.
Command buffer
We have already worked with a command buffer when we copied data from the CPU to the GPU, so you should be familiar with the concept. As you recall, command buffers are allocated from a command pool. Technically, we could create a pool, allocate a command buffer from it, and record everything in advance as we repeat the same work from frame to frame. But that’s not how it’s usually done. Allocating a command buffer is a cheap operation, and it’s fine to allocate new buffers every frame. But if we keep allocating every frame, we will run out of memory. So here is our strategy:
-
we create multiple command pools - corresponding to the number of frames in flight (2). This is necessary to avoid waiting.
-
before we get a command buffer, we reset a current pool. From the Specification:
Resetting a command pool recycles all of the resources from all of the command buffers allocated from the command pool back to the command pool. All command buffers that have been allocated from the command pool are put in the initial state.
Resetting a pool resets all the command buffers at once and we can reuse them. If we have only one pool, it would be an undefined behavior to reset it - the command buffers of the previous frame could still be processed by the GPU. That’s why we need more than one. And after waiting for a fence, it is safe to reset. The same strategy as for uniform buffers.
-
next, we try to get a command buffer. We keep track of available and used command buffers. These two lists are stored in teapot::VukanData and are called
available_command_buffersandused_command_buffers. Actually, these are lists of lists - again, we have a separate collection for each frame in the flight. Ifavailable_command_buffersis not empty for the current frame, we simply get a buffer from it and mark the buffer as used by putting it inused_command_buffers. Ifavailable_command_buffersis empty, we allocate a set of new buffers and place them all inavailable_command_buffers.
Command pools command_pools are stored in teapot::VukanData and are created with the teapot::create_command_pools function. Here we create CONCURRENT_RESOURCE_COUNT number of pools by calling the function ash::Device::create_command_pool . The pools are created with the flag ash::vk::CommandPoolCreateFlags::TRANSIENT, which means “that command buffers allocated from the pool will be short-lived, meaning that they will be reset or freed in a relatively short timeframe. This flag may be used by the implementation to control memory allocation behavior within the pool”.
In the vulkan_draw::draw module, a current command buffer is reset in the vulkan_draw::reset_command_pool function by calling the ash::Device::reset_command_pool function. The ash::vk::CommandPoolResetFlags::RELEASE_RESOURCES flag provided to the function means “that resetting a command pool recycles all of the resources from the command pool back to the system”.
In the vulkan_draw::draw function, a command buffer is obtained by the vulkan_draw::get_command_buffer function. Here, a new buffer is allocated by calling the function ash::DeviceV::allocate_command_buffers. With the field ash::vk::CommandBufferLevel::PRIMARY we specify the level of the buffer. There are two levels of command buffers - primary and secondary. The Specification:
There are two levels of command buffers - primary command buffers, which can execute secondary command buffers, and which are submitted to queues, and secondary command buffers, which can be executed by primary command buffers, and which are not directly submitted to queues.
We use only primary command buffers in the application.
Once we have the command buffer, we need to put it in a record state. A command buffer can be in one of several states, but individual commands can only be written to the buffer that is in the Recording state. For this purpose, we must begin the command buffer. This is done by calling the function vulkan_draw::begin_command_buffer. Here we call the function ash::Device::begin_command_buffer and specify the buffer usage as ash::vk::CommandBufferUsageFlags::ONE_TIME_SUBMIT. This flag says “that each recording of the command buffer will only be submitted once, and the command buffer will be reset and recorded again between each submission”. You recall that we reset a buffer by resetting a command pool.
Render pass
Remember that drawing in Vulkan can only be done as part of a render pass. It is a must. For example, if you open the documentation for the vkCmdDrawIndexed command and scroll to the Command Properties section, you will notice that the command can only be called within a render pass. Also, some additional states are set at the beginning of a render pass. We begin a render pass by calling the vulkan_draw::begin_render_pass function. We start by filling the ash::vk::RenderPassBeginInfo structure:
render_pass- the render pass we want to begin.framebuffer- remember how we created multiple framebuffers in the previous step - one for each image in the swapchain. Now we tell that we want to draw into a swapchain image with indeximage_indexwe got earlier.render_area- we want to draw into the entire surface.clear_values- if you look at the create_render_pass function, you will remember that theload_opof the single attachment (which is a swapchain image) isash::vk::AttachmentLoadOp:: CLEAR. This means that we need to specify a clear value for it and the attachment will be set to that color. It is possible to have multiple attachments (render targets) and in this case we need to specify multiple clear values.
We pass this info structure to the function ash::Device::cmd_begin_render_pass. Together with info we pass our command buffer. The argument ash::vk::SubpassContents:: INLINE simply says that we will continue to write commands to the provided buffer. The beginning and the ending of a render pass can only be called using the primary command buffer, but it is also possible to use secondary command buffers for commands within a render pass. In this case ash::vk::SubpassContents::SECONDARY_COMMAND_BUFFERS will be used and all commands on the primary buffer are forbidden until the end of the render pass or subpass.
Vieport and scissor
Recall how we used dynamic state when creating a pipeline. We set ash::vk::DynamicState:: VIEWPORT and ash::vk::DynamicState:: SCISSOR. Now before you call a draw command, this state should be satisfied. We set the vieport in the function vulkan_draw::set_viewport and scissor in vulkan_draw::set_scissor.
Descriptors
Recall that so far we have not specified the actual resources we want to use for a particular frame. We have created the descriptor set layout that specifies the types of resources. But before we draw, we want to assign the right buffers to the right slots. To do this, we need to allocate descriptor sets and update descriptors. Descriptor management is similar to command buffer management - we have multiple descriptor pools - one for each frame in flight. First, we reset a current pool. Unlike resetting a command pool, which resets command buffers but does not release them, resetting a descriptor pool implicitly releases the descriptor sets allocated from that pool. We then allocate and update a new set. Again, we need multiple pools because we can not reset a pool until all previously assigned tasks have been completed.
Descriptor pools are stored in the descriptor_pools field of the teapot::VulkanData structure and created using the teapot::create_descriptor_pools function. When we open the teapot::create_descriptor_set_layout function, we will recall that we need one descriptor set with 3 bindings - 2 for the storage buffers and 1 for the uniform buffer. We can find the same information in the shaders - our vertex and tessellation evaluation shaders declare sets and bindings. So when we create a pool, we can safely specify the number of sets as 1 and the number of descriptors as 2 and 1 for the different descriptor types. But in real life, we usually do not know how many descriptors we need to use in a given frame, as this number can vary. Therefore, a good strategy would be to create a pool that has enough space to hold many sets with many different descriptors. This is exactly what we do in the function:
- we have 2 pool sizes - one for 100 descriptors of type
ash::vk::DescriptorType::STORAGE_BUFFERand another for 100 descriptors of typeash::vk::DescriptorType::UNIFORM_BUFFER. - in create info we specify the maximum number of sets as 100.
- we create
CONCURRENT_RESOURCE_COUNTnumber of pools.
A pool is created by calling the function ash::Device::create_descriptor_pool.
It is important to understand how pool sizes and maximum number of sets work. New descriptors can be allocated until there is enough space in the pool. Let us take our pool configuration as an example with 100 maximum sets, 100 storage descriptors, and 100 uniform descriptors. If we have a descriptor set layout with 1 storage and 1 uniform descriptor, we can allocate 100 sets. If another layout uses 50 storage descriptors, we can allocate only 2 sets - 50 * 2 = 100 - the maximum number of storage descriptors is reached. Or if a third layout uses 50 storage and 100 uniform descriptors, we can allocate only 1 set. If there is no more space in the pool, another pool should be created.
Reseting a pool happens in vulkan_draw::reset_descriptor_pool function. Here we call ash::Device::reset_descriptor_pool with the current descriptor pool.
After we free the pool’s space, we can allocate a descriptor set. As was described above, we need to handle a situation when the pool is full, but in our case, we know for sure that the allocation will succeed because we need only one set. We allocate a set in vulkan_draw::allocate_descriptor_set function, where we call ash::Device::allocate_descriptor_sets function. We pass the current descriptor pool from which we want to allocate a set and the descriptor set layout. The function returns a vector of allocated sets, but since in the layout (and shaders) we declared a single set, we take the first (and only) element.
With the newly allocated descriptor set, we need to update it with real data. I.e., we need to tell which resources go to which binding slots. We do this in vulkan_draw::update_descriptor_set function. Recall that we have 3 buffers - control points, patch instances, and uniform. We create 3 ash::vk::DescriptorBufferInfo instances where we store a buffer with its data range. Notice how the first 2 buffers are passed directly, but a uniform buffer is selected from the list. This is because positions and data are static, but a uniform buffer needs to be updated every frame. And again, we select a buffer where it is safe to write in the current frame. Next, we create 3 ash::vk::WriteDescriptorSet instances where we specify a set to update, info, type, and a binding slot. We specified a type in so many places - when creating a buffer when created the descriptor set layout, and we still need to do it here as well. This is because objects in Vulkan are just handles and don’t have a state. If we make a mistake, in the best case, we’ll see nothing, and in the worst case, the system will crash. Luckily, the layers keep the state and can find any error we make. Finally, we call the ash::Device::update_descriptor_sets function, which updates the set with correct data pointers.
Uniform buffer
While the control points and patch data both hold ready-to-use information, a uniform buffer is empty - we never updated it. In the vulkan_draw::draw function, we get a current uniform buffer (the same one we used to update a descriptor set above) and write a previously calculated matrix into it. We use the cgmath crate for the math. With the help of the bytemuck crate, we cast the matrix data to bytes and copy 16 * 4 bytes of data to the mapped memory.
Recall that when we created the uniform buffers in vulkan_data back in step 3, we used a memory location flag as gpu_allocator::MemoryLocation::CpuToGpu. The gpu_allocator crate guarantees that memory with this flag has ash::vk::MemoryPropertyFlags::HOST_VISIBLE and ash::vk::MemoryPropertyFlags::HOST_COHERENT properties. In other words, it guarantees memory coherency, and we do not need to flush caches manually.
Push constant
It was perfectly fine to write the tesselation level in a uniform buffer, but for learning purposes, we decided to set it via push constants. The push constants mechanism allows writing a small amount of data directly into a command buffer. We discussed this when we created a pipeline layout where we declared a single float to be used in the tesselation control shader. We write the value by calling the ash::Device::cmd_push_constants function. Here we pass the pipeline layout, shader stage, offset (we have a single value so offset is 0), and the byte representation of the tesselation level. When the GPU starts executing this command buffer, it will copy this value to GPU registers, and this is how the data ends up on the device.
Binding
When we updated a descriptor set above, we just wrote where to find certain data for certain descriptors. We can have many descriptor sets for different draw calls, and we need to specify which one we want to use for the next draw call. All we need to do is bind the updated descriptor set by calling the ash::Device::cmd_bind_descriptor_sets function. As the function name suggests, we can bind multiple sets at once. We have one set, and we bind it to slot 0. Dynamic offsets (the last parameter) are used with dynamic-uniform or storage buffers which are not a part of these series.
Next, we need to tell the GPU which state to use for the next draw call. We do it with the ash::Device::cmd_bind_pipeline function. Depending on the user input, the wireframe or solid pipeline is chosen.
Though we used a descriptor set to specify buffers we want to use in the shaders, not all buffers are treated equally. Vertex and index buffers are special. When using a vertex shader, we can specify how we want to see data in a shader by providing a vertex input state. For example, we can tell that we want a single u32 vertex value to become vec4 (with the format VK_FORMAT_R8G8B8A8_UNORM) in the shader, which we can’t do with uniform or storage buffers. On the other hand, the index buffer is a must-have for complex geometry. First of all, as you probably know, it allows reducing memory usage by using an index pointing to a vertex buffer. In this case, the vertex buffer will hold unique vertices, and any duplication will be handled by repeating indices in the index buffer. Another useful feature is vertex caching. If the GPU processes a vertex that already was calculated (and if it’s in the cache), it will just get the data from the cache instead of running a shader one more time. For our application, we decided not to use a vertex shader. But we have the index buffer, which we bind with the ash::Device::cmd_bind_index_buffer function. We have a small number of patches with a small number of points, and 16-bit indices are enough, so together with the index buffer, we pass the ash::vk::IndexType::UINT16 type.
Drawing
To tell the GPU to draw, we call the ash::Device::cmd_draw_indexed function. The word indexed in the name says that this command has to be used with an index buffer. We already bound the buffer, and now we want to draw patch_point_count indices from that buffer.
Ending render pass and command buffer
Every render pass that began must be ended. The same is with command buffers. We do it by calling ash::Device::cmd_end_render_pass and ash::Device::end_command_buffer functions.
Submiting
At this point, we recorded all commands necessary to draw a teapot. Now we need to send our command buffer to the GPU. We do it by submitting the buffer to a queue. Do you remember the function where we selected a queue family? Notice how we requested the queue that supports graphic operations. Now we submit the command buffer to that queue by calling the submit function. Inside this function we call the function ash::Device::queue_submit. Here we pass a submit info where we specify:
wait_semaphores- the execution of the command buffer will not start until all these semaphores are in signaled state. We pass only one semaphore -VulkanData::image_available_semaphore. That is the same semaphore we used in theget_image_indexfunction when got the next swapchain image index. Back then, we passed this semaphore intoash::Device::acquire_next_image, asking to set it to the signaled state as soon as the presentation engine finishes with the swapchain image. We shouldn’t start to draw anything into the image until it’s busy.wait_dst_stage_mask- if we specified a semaphore, we must specify a pipeline stage where the GPU will wait for this semaphore. In our case, we wait inash::vk::PipelineStageFlags::COLOR_ATTACHMENT_OUTPUT- ” the stage of the pipeline after blending where the final color values are output from the pipeline”. In other words, the GPU will not write a final value into the image until the semaphore is in signaled state.cmd_buffers- our recorded command buffer.signal_semaphores- “the list of semaphores to be signaled once the commands specified in command buffers for this batch have completed execution”. We have a semaphore that controls when the GPU is allowed to write to a swapchain image. But we also want to present this image, i.e., show it on the screen. And we want to do it when the image is complete. So we need another semaphore for this that should signal when we can present. This semaphore is defined in VulkanData struct and calledVulkanData::rendering_finished_semaphore. We create it in the function vulkan_utils::create_semaphore and it’s identical to theVulkanData::image_available_semaphore.
We pass the Submit info into the ash::Device::queue_submit function together with the queue and a fence. That is the fence that we’ll wait in the vulkan_draw::wait_resource_available function two frames later.
Presenting
When a swapchain is ready, we want to present it. In the function vulkan_draw::present we create a ash::vk::PresentInfoKHR struct with the following data:
wait_semaphores- therendering_finished_semaphoresemaphore from the previous step.swapchains- our swapchain.indices- the image index in the swapchain.
We pass the info into the ash::extensions::khr::Swapchain::queue_present function. Also we pass the queue. This queue should be capable of presentation to the surface. In get_queue_family function we made sure that our queue can do it by calling ash::extensions::khr::Surface::get_physical_device_surface_support function.
NOTE: interesting that there is a semaphore to wait, but no way to pass a stage where to wait for it. This is one of the rare cases where the API synchronizes automatically: “Any writes to memory backing the images referenced by the
pImageIndicesandpSwapchainsmembers ofpPresentInfo, that are available beforevkQueuePresentKHRis executed, are automatically made visible to the read access performed by the presentation engine. This automatic visibility operation for an image happens-after the semaphore signal operation, and happens-before the presentation engine accesses the image”.
The queue_present function can return many different results. We are handling the codes ash::vk::Result::SUBOPTIMAL_KHR and ash::vk::Result::ERROR_OUT_OF_DATE_KHR, which are returned when the swapchain was resized. In this case, the draw function returns Ok(false), and in the next frame, the swapchain will be rebuilt.
Clean
We created some new objects and all they should be destroyed on application exit. As usual, we do it in the VulkanData::clean function.
Result
It’s finally done! If we now run the application, we’ll see our teapot! The rendering mode can be changed to wireframe or solid by pressing a spacebar. The tesselation level can be increased or decreased by pressing + or - on the Numpad. Here’s the screenshot of the running application:

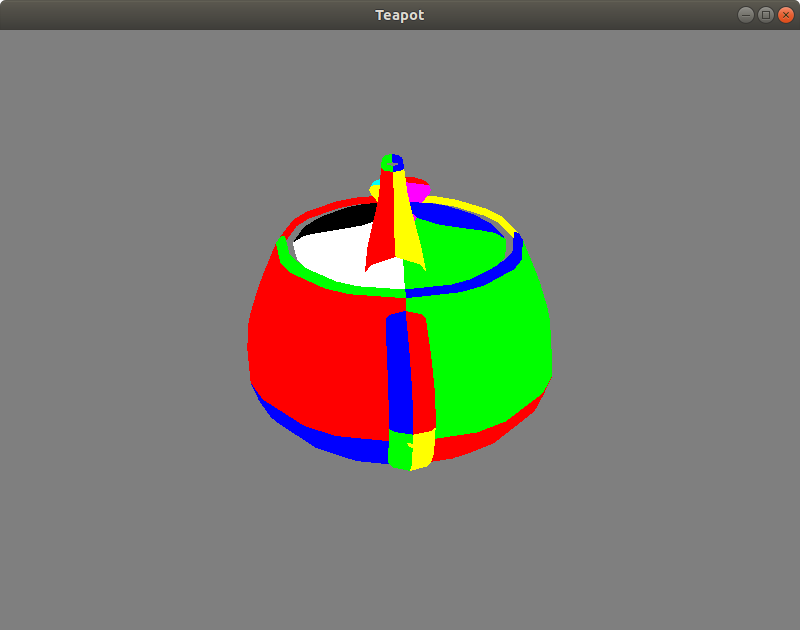
But wait, there is something wrong - if we look at the spout, we’ll see that it’s in the wrong place. And if we continue to look more carefully, we’ll see that some patches that should be on the backside appear in front of the model. What’s going on? Of course, we never dealt with the depth. We completely forgot about a depth buffer. No worries, next time, we’ll fix that.
Conclusion
GPU does its job by executing a batch of commands, which are recorded in a command buffer. Command buffers are allocated from a command pool, which is considered a fast operation, so it’s ok to allocate new buffers every frame. These command buffers are submitted to a queue. Some commands work only with specific queue types.
Telling the GPU which resource to use in a shader is done through descriptors. One descriptor holds a type of resource and a pointer to data. Descriptors submitted to the gpu via descriptor sets. New descriptors are allocated from descriptor pools. In opposite to a command pool where the number of allocations is unknown, it’s required to specify the number of sets and the number of descriptors the pool can hold. Allocating from a pool is also considered a fast operation. Before binding a set, descriptors have to be updated with the actual data. This is considered an expensive operation, and some caching mechanisms could be a good idea.
It’s important to record command buffers and update descriptor sets when they are not in use by the GPU. For this, synchronization is needed, for example, a fence that tells the host when the GPU is finished with a buffer or a descriptor set.
Writing to a framebuffer should be done when a swapchain image is not used by the presentation engine. Similarly, the presenting should be done when the image is completely written. Such kind synchronizations are done with semaphores.
Let’s update the diagram with all the things we have done today:

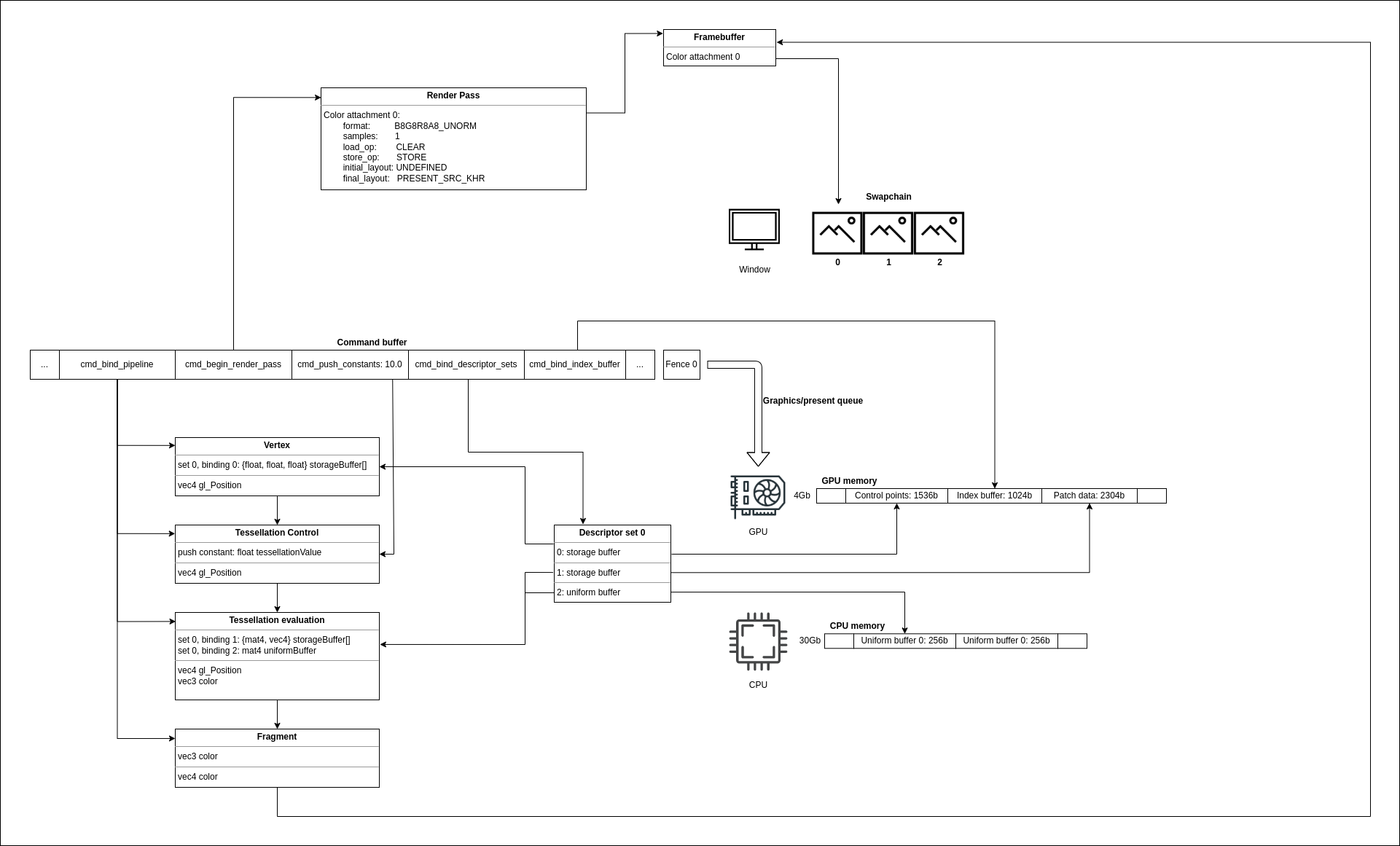
Notice how everything is tied now. The descriptor set points to correct memory areas, and shaders use these areas to get data. Stating a render pass ties the render pass object and the framebuffer, and now the fragment shader knows where to write pixel data. The command buffer provides a lot of information, including push constant and index buffer information.
What next
Today we got the first image. It’s not perfect because the polygons are drawn out of order. In the next last step, we’ll add the depth buffer to fix the problem.
The source code for this step is here.
You can subscribe to my Twitter account to be notified when the new post is out or for comments and suggestions. If you found a bug, please raise an issue. If you have a question, you can start a discussion here.